Sobriété numérique : le Knowledge Graph et le Product Graph comme leviers écologiques
Découvrez comment structurer vos données avec le Knowledge Graph et le Product Graph réduit l'empreinte carbone de votre site. Une stratégie SEO/GEO pour un web plus performant et durable et une sobriété numérique assumée.
LYDIE GOYENETCHE
6/15/202621 min lire
Le paradoxe de la transition numérique dans un climat en mutation
Le réchauffement climatique n'est plus une projection théorique, mais une réalité tangible qui redessine les paysages de nos territoires. En France, le littoral basque subit une érosion accélérée et des canicules marines inédites, tandis qu'au Canada, les feux de forêt de plus en plus intenses et fréquents témoignent d'une transformation profonde des écosystèmes boréaux. Dans ce contexte d'urgence, la transition numérique est souvent présentée comme une solution de dématérialisation. Pourtant, elle porte en elle sa propre contradiction.
L'infrastructure du web, des centres de données aux réseaux sociaux, repose sur une consommation physique et énergétique massive. Selon les travaux de l'ADEME (Agence de la Transition Écologique), le numérique représente aujourd'hui une part significative de l'empreinte carbone mondiale, une empreinte qui croît proportionnellement à l'augmentation des flux de données et au renouvellement effréné des équipements.
Il existe un paradoxe fondamental : alors que nous utilisons le numérique pour informer, sensibiliser et optimiser nos consommations locales (notamment à travers le SEO local et le Knowledge Graph), la pollution invisible générée par ces mêmes outils accentue le dérèglement climatique.
Comprendre l'impact du numérique sur le climat, c'est accepter que chaque requête Google, chaque consultation de fiche Google Business Profile, et chaque interaction sur les réseaux sociaux possède un coût environnemental. En tant que consultante SEO & GEO, mon approche consiste à démontrer que la structuration des données — par le biais du Knowledge Graph et du Product Graph — n'est pas seulement un levier de visibilité commerciale, mais un outil essentiel de sobriété numérique : en guidant l'utilisateur de manière ultra-précise vers l'information ou le produit local recherché, on réduit le volume de données transitant inutilement sur le réseau, limitant ainsi l'empreinte carbone associée à chaque recherche.
Quand la donnée devient un poids mort : l'envers du décor numérique
Pour comprendre pourquoi le Knowledge Graph (KG) et le Product Graph (PG) peuvent devenir des leviers de sobriété numérique, il faut d'abord regarder ce qui se cache derrière chaque résultat affiché sur Google. Comme le rappelle Frédéric Bordage, fondateur de GreenIT et pionnier de la sobriété numérique en France, « le numérique est avant tout une industrie lourde ». Derrière chaque recherche se trouvent des centres de données, des kilomètres de fibre optique, des serveurs, des systèmes de refroidissement et des infrastructures énergétiques bien réelles.
Selon les chiffres actualisés par l'ADEME en janvier 2025, le numérique représentait déjà 4,4 % de l'empreinte carbone française en 2022, soit 29,5 millions de tonnes de CO₂ équivalent. Pour donner un ordre de grandeur, cela représente un impact comparable à celui de l'ensemble du transport routier de marchandises en France. Si aucune mesure n'est prise, cette empreinte pourrait tripler d'ici 2050.
Knowledge Graph et Product Graph : deux infrastructures, deux logiques énergétiques
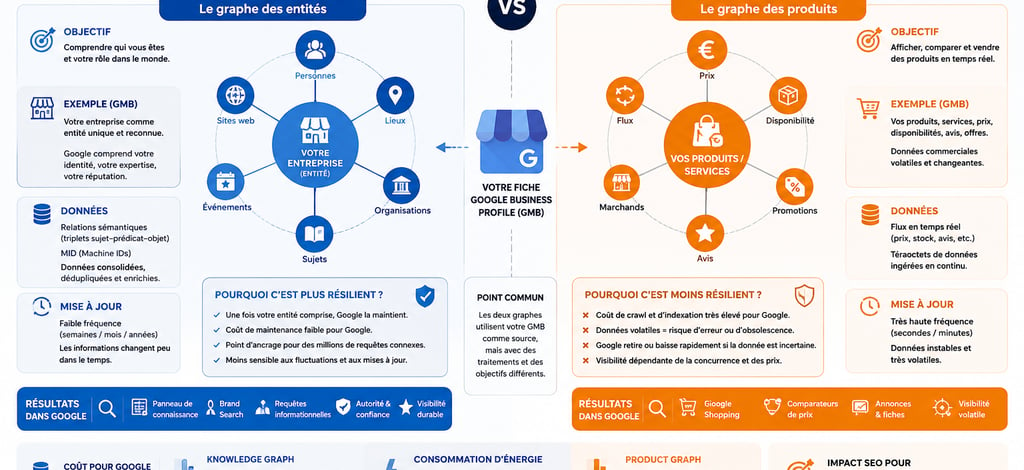
L'infographie illustre parfaitement une différence souvent ignorée.
Le Knowledge Graph fonctionne comme une gigantesque carte d'identité numérique. Google cherche à comprendre une entité : une entreprise, un restaurant, un hôtel, une mairie ou une personnalité. Une fois cette compréhension établie, les données évoluent peu. Une adresse, un numéro de téléphone ou une activité principale peuvent rester inchangés pendant plusieurs années.
Le Product Graph suit une logique radicalement différente. Il traite des informations commerciales instables : prix, promotions, stocks, disponibilités, avis ou caractéristiques techniques. Certaines données peuvent changer plusieurs dizaines de fois par jour.
Bill Slawski, spécialiste historique du fonctionnement des moteurs de recherche, expliquait déjà avant son décès que Google cherche en permanence à réduire ses coûts de calcul en privilégiant les données les plus fiables et les plus stables. Le Knowledge Graph répond précisément à cette logique d'économie computationnelle.
On pourrait comparer le Knowledge Graph à la construction du cadastre d'une ville : un investissement initial important mais relativement stable dans le temps. Le Product Graph ressemble davantage aux panneaux d'affichage électroniques d'un supermarché qui doivent être actualisés en permanence.
Derrière chaque recherche : une consommation électrique bien réelle
En avril 2025, l'Agence Internationale de l'Énergie (AIE) estimait que les centres de données avaient consommé environ 415 TWh d'électricité en 2024, soit 1,5 % de toute l'électricité mondiale. À titre de comparaison, cette consommation est supérieure à celle de nombreux pays industrialisés et équivaut pratiquement à la consommation annuelle d'un pays comme la France.
L'AIE prévoit également que cette consommation pourrait atteindre 945 TWh en 2030 sous l'effet de l'intelligence artificielle, soit plus du double en seulement 6 ans. Fatih Birol, directeur exécutif de l'AIE, considère désormais les centres de données comme l'un des nouveaux moteurs de croissance de la demande énergétique mondiale.
Dans ce contexte, chaque requête évitée, chaque page inutilement crawlée en moins et chaque donnée correctement structurée deviennent des éléments participant à l'efficacité globale du système.
Le Product Graph : la logique du flux permanent
L'infographie montre que le Product Graph repose sur des flux continus de données : prix, promotions, avis, marchands et disponibilités.
Contrairement au Knowledge Graph, Google doit vérifier régulièrement que les informations sont encore exactes. Cette nécessité multiplie les opérations de crawl, d'indexation et de recalcul.
Pour comprendre l'ampleur du phénomène, imaginons une grande surface de 50 000 références. Si chaque prix évolue plusieurs fois par semaine, les moteurs doivent continuellement vérifier, comparer et réindexer les informations. Nous ne sommes plus dans la logique d'une bibliothèque que l'on classe une fois pour toutes, mais dans celle d'un marché dont chaque étal change en permanence.
C'est la raison pour laquelle l'infographie souligne que le Product Graph possède un coût de maintenance et d'indexation beaucoup plus élevé que le Knowledge Graph.
L'obésité logicielle : quand le web transporte des camions pour livrer une enveloppe
Le problème n'est pas uniquement lié aux moteurs de recherche. Il provient également de la manière dont les sites sont conçus.
Selon les données du HTTP Archive, le poids moyen d'une page web est passé d'environ 700 Ko en 2010 à plus de 2,5 Mo aujourd'hui. En quinze ans, le poids moyen des pages a donc été multiplié par plus de 3. Chaque visite implique davantage de transferts de données, davantage de calculs et davantage de stockage.
Frédéric Bordage compare souvent cette situation à l'envoi d'un camion de déménagement pour livrer une simple lettre. Une grande partie des scripts, animations, trackers et extensions chargés par les sites modernes n'apporte aucune valeur réelle à l'utilisateur.
GMB, Knowledge Graph et réduction des requêtes inutiles
C'est ici que le Knowledge Graph prend tout son sens.
Lorsque votre fiche Google Business Profile est correctement renseignée, Google peut accéder directement à vos horaires, votre adresse, vos services ou vos coordonnées sans devoir explorer des dizaines de pages.
Le moteur ne cherche plus l'information ; il la connaît déjà.
Cette logique rejoint les travaux de Geoffrey Hinton, prix Nobel de physique 2024 et l'un des pères de l'intelligence artificielle moderne, qui explique que l'enjeu des systèmes intelligents n'est plus seulement d'accumuler des données mais de structurer efficacement la connaissance afin de réduire les calculs inutiles.
Un horaire disponible directement dans le Knowledge Graph peut éviter plusieurs pages consultées, plusieurs requêtes serveur et plusieurs opérations d'indexation répétées.
Pourquoi le Knowledge Graph est plus résilient
Comme l'indique l'infographie, le Knowledge Graph repose sur des données consolidées, dédupliquées et enrichies.
Une fois votre entité comprise, Google peut réutiliser cette connaissance dans des millions de requêtes sans devoir reconstruire son analyse à chaque recherche.
C'est exactement ce que décrit David Amerland, spécialiste du Knowledge Graph : Google cherche à passer d'un moteur de recherche à un moteur de compréhension.
L'investissement initial est élevé, mais le coût marginal devient extrêmement faible.
À l'inverse, le Product Graph doit continuellement recalculer la réalité commerciale du marché.
Dans une période où les centres de données consomment déjà 415 TWh par an et où leur demande énergétique pourrait doubler avant 2030, cette différence entre données stables et données volatiles devient également une question de durabilité environnementale.
E-commerce, inflation des données et Core Updates : quand Google nettoie son propre climat numérique
L'explosion du e-commerce : une croissance qui multiplie les données
Depuis la pandémie de 2020, le commerce en ligne a connu une accélération spectaculaire. Selon la CNUCED (Conférence des Nations unies sur le commerce et le développement), le e-commerce mondial représentait environ 26 700 milliards de dollars en 2019 et dépassait déjà 32 000 milliards de dollars en 2022. Chaque produit vendu en ligne génère désormais une multitude de données : descriptions, photos, prix, stocks, avis clients, promotions, vidéos, FAQ, données structurées et informations logistiques.
Pour le chercheur britannique Tim Berners-Lee, inventeur du World Wide Web :
« Le défi n'est plus de produire davantage de données mais de leur donner du sens. »
Cette croissance ressemble à une métropole qui doublerait sa population sans agrandir ses routes : les informations continuent d'affluer, mais les infrastructures chargées de les organiser doivent fournir toujours plus d'efforts.
Product Graph : le grand bénéficiaire de l'explosion du commerce en ligne
L'infographie montre que le Product Graph repose sur des données dynamiques : prix, promotions, avis, disponibilité ou stocks. Or le nombre de produits référencés sur Internet a explosé. Amazon comptait déjà plus de 350 millions de références produits en 2024, tandis que Google Merchant Center traite des milliards d'offres commerciales provenant de commerçants du monde entier.
Selon Bill Ready, président de Google Commerce :
« L'objectif est de rendre l'information commerciale accessible en temps réel. »
Le problème est qu'une donnée commerciale n'est jamais totalement stable. Un stock peut changer plusieurs fois par heure. Un prix peut être modifié plusieurs fois dans la journée. À l'échelle mondiale, cela revient à mettre à jour les panneaux d'affichage de toutes les grandes surfaces de la planète simultanément.
Knowledge Graph : une croissance plus lente mais plus durable
Face à cette inflation du Product Graph, le Knowledge Graph suit une logique différente. Créé officiellement par Google en 2012, il cherche à comprendre les entités : entreprises, personnes, lieux, organisations ou événements.
Selon Google, le Knowledge Graph contenait déjà plus de 500 milliards de faits concernant 5 milliards d'entités en 2020. Pourtant, cette croissance reste relativement maîtrisée. Une entreprise ne change pas d'adresse tous les jours. Une ville ne modifie pas son nom chaque semaine.
Pour David Amerland, spécialiste du Knowledge Graph :
« Les entités apportent de la stabilité dans un environnement numérique devenu extrêmement volatile. »
La différence est comparable à celle entre un registre d'état civil et un catalogue promotionnel de supermarché. Le premier évolue lentement. Le second est constamment renouvelé.
Quand les contenus deviennent une forme de pollution numérique
Pendant de nombreuses années, le SEO a encouragé une logique quantitative : produire toujours plus de contenus, plus de pages catégories, plus de fiches produits et plus de textes optimisés.
Résultat : des millions de pages presque identiques ont envahi le web.
Selon une étude publiée par Ahrefs en 2024, près de 96,5 % des pages publiées sur Internet ne reçoivent aucun trafic organique significatif depuis Google.
Pour John Mueller, Search Advocate chez Google :
« La plupart des contenus publiés aujourd'hui n'apportent aucune information réellement nouvelle. »
Cette situation ressemble à une bibliothèque qui recevrait chaque jour des milliers de copies identiques du même livre. Les coûts de stockage augmentent tandis que la valeur de l'information reste inchangée.
L'intelligence artificielle amplifie encore le phénomène
Depuis le lancement de ChatGPT fin 2022, la production de contenus automatisés a explosé. Plusieurs études estiment que des dizaines de millions de pages générées par IA sont publiées chaque mois.
Selon Geoffrey Hinton, prix Nobel de physique 2024 et pionnier de l'intelligence artificielle :
« La difficulté n'est plus de produire du contenu mais de distinguer le signal du bruit. »
Cette inflation documentaire oblige les moteurs à consacrer davantage de ressources informatiques pour identifier les contenus réellement utiles.
C'est un peu comme chercher une aiguille dans une botte de foin qui grossit chaque jour.
Les Core Updates : les opérations de nettoyage du web
Les Core Updates de Google prennent une importance particulière dans ce contexte.
La Core Update de mars 2024 a été présentée par Google comme l'une des plus importantes de la décennie. L'entreprise annonçait vouloir réduire de 40 % les contenus jugés peu utiles ou créés principalement pour les moteurs de recherche.
Pour Danny Sullivan, porte-parole de Google Search :
« Notre objectif est d'afficher davantage de contenus satisfaisants et moins de contenus conçus uniquement pour attirer du trafic. »
D'un point de vue environnemental, ces mises à jour ressemblent à des opérations de tri sélectif dans une décharge devenue trop volumineuse.
Les pages zombies : une dette carbone invisible
Chaque page conservée inutilement dans un site web continue d'être :
stockée ;
sauvegardée ;
explorée ;
parfois réindexée.
Les spécialistes du SEO parlent souvent de « pages zombies ».
Sur certains sites e-commerce, ces pages représentent plus de 50 % des URL existantes.
Pour Cindy Krum, spécialiste reconnue du SEO mobile :
« Les moteurs de recherche préfèrent de plus en plus la qualité structurelle à la quantité documentaire. »
La comparaison est simple : chauffer une maison dont la moitié des pièces sont abandonnées augmente inutilement la facture énergétique.
Pourquoi Google favorise désormais la précision sémantique
Dans un contexte où les centres de données mondiaux ont consommé environ 415 TWh d'électricité en 2024 selon l'AIE, Google cherche naturellement à optimiser ses ressources.
Une donnée structurée correctement intégrée au Knowledge Graph ou au Product Graph peut être comprise immédiatement.
À l'inverse, un contenu mal organisé nécessite davantage :
de crawl ;
de calcul ;
d'interprétation ;
de stockage.
Comme le rappelle Frédéric Bordage, fondateur de GreenIT :
« Le meilleur octet est celui que l'on n'a pas besoin de produire, stocker ou transporter. »
Du SEO de volume au SEO de sobriété
Les Core Updates traduisent finalement une évolution profonde de la recherche.
Pendant vingt ans, les entreprises ont cherché à produire toujours plus de contenus.
Aujourd'hui, Google pousse progressivement vers une logique différente :
moins de pages ;
moins de duplication ;
plus de structuration ;
plus de fiabilité.
Le Knowledge Graph permet de stabiliser les connaissances.
Le Product Graph permet de transmettre efficacement les informations commerciales.
Les Core Updates agissent comme un mécanisme de régulation destiné à éviter que les bases de données mondiales ne deviennent ingérables.
À l'heure où l'AIE prévoit une consommation électrique des centres de données proche de 945 TWh en 2030, soit davantage que la consommation actuelle du Japon, la sobriété numérique n'est plus uniquement un enjeu écologique. Elle devient une nécessité technique pour garantir la pérennité du web lui-même.
Conclusion – La sobriété numérique ne consiste pas à supprimer la donnée, mais à la rendre utile
À première vue, les constats dressés dans cet article pourraient conduire à une conclusion radicale : puisque les centres de données ont consommé environ 415 TWh d'électricité en 2024 selon l'Agence Internationale de l'Énergie, puisque le numérique représentait déjà 4,4 % de l'empreinte carbone française en 2022 selon l'ADEME, et puisque les moteurs de recherche consacrent une part croissante de leurs ressources à traiter des contenus redondants ou inutiles, il suffirait de produire moins de données.
La réalité est beaucoup plus nuancée.
Depuis plusieurs années, Google a progressivement séparé deux univers sémantiques distincts : d'un côté les données informationnelles qui alimentent le Knowledge Graph, de l'autre les données transactionnelles qui alimentent le Product Graph. Cette séparation n'est pas un détail technique ; elle reflète deux intentions de recherche radicalement différentes.
Lorsqu'un utilisateur cherche à comprendre un sujet, à identifier une entreprise ou à explorer un domaine d'activité, Google mobilise principalement le Knowledge Graph. Lorsqu'il cherche un produit, un prix, une disponibilité ou un stock local, le moteur s'appuie davantage sur le Product Graph. Comme l'explique Bill Ready, responsable de Google Commerce, l'objectif est désormais de fournir non seulement une réponse pertinente, mais également une réponse immédiatement exploitable.
Autrement dit, l'enjeu n'est pas de supprimer la donnée mais d'injecter la bonne donnée au bon endroit.
Sans Product Graph, la conversion devient difficile
Un site web d'entreprise qui ne possède pas de pages produits enrichies par des données structurées transactionnelles se prive d'une part importante de sa visibilité commerciale.
Lorsqu'un internaute recherche un produit ou un service précis, Google privilégie désormais les contenus capables de répondre immédiatement à des questions telles que :
Quel est le prix ?
Le produit est-il disponible ?
Où puis-je l'acheter ?
Est-il en stock près de chez moi ?
Sans ces informations structurées, le moteur dispose de peu d'éléments pour orienter l'utilisateur vers l'entreprise concernée.
La comparaison est simple : c'est comme ouvrir un magasin sans afficher ni les prix ni les horaires d'ouverture. Le commerce existe, mais il devient beaucoup plus difficile à trouver et à utiliser.
Dans un contexte où Google traite plusieurs milliards de recherches commerciales chaque jour, les entreprises qui alimentent correctement le Product Graph disposent d'un avantage concurrentiel évident.
Sans Knowledge Graph, difficile de devenir une référence
À l'inverse, une entreprise qui n'investit pas dans son Knowledge Graph limite fortement sa capacité à apparaître dans les recherches exploratoires.
Pour être cité par les moteurs de recherche, les assistants conversationnels ou les IA génératives, il faut exister comme entité identifiable.
C'est précisément le rôle du Knowledge Graph.
Comme l'explique David Amerland :
« Les moteurs de recherche évoluent d'un modèle fondé sur les mots vers un modèle fondé sur les entités. »
Sans nœud d'autorité clairement identifié, une entreprise reste une simple page parmi plusieurs milliards d'autres.
Dans un web qui compte désormais plus de 1,1 milliard de sites internet, selon les estimations de Netcraft en 2025, l'autorité sémantique devient un facteur de différenciation majeur.
La limite naturelle de Google Business Profile
Certaines entreprises pourraient être tentées de renoncer à leur site web et de concentrer tous leurs efforts sur leur fiche Google Business Profile.
Pour certaines activités très locales — artisans, coiffeurs, restaurants de quartier ou commerces de proximité — cette stratégie peut fonctionner pendant un temps.
Cependant, Google Business Profile possède une limite structurelle : son rayon d'influence reste fortement dépendant de la proximité géographique.
Dans la plupart des secteurs, la visibilité organique d'une fiche est particulièrement forte dans un rayon d'environ 10 à 15 kilomètres autour du point de vente. Au-delà, la concurrence locale, la personnalisation des résultats et les critères de pertinence réduisent fortement sa capacité d'exposition.
La comparaison est celle d'un phare côtier. Il éclaire parfaitement son environnement immédiat mais ne permet pas de traverser un océan.
Une entreprise qui souhaite développer une clientèle régionale, nationale ou internationale doit nécessairement s'appuyer sur un actif numérique plus vaste que sa seule fiche locale.
Le véritable choix n'est pas entre produire ou ne pas produire des données
Le débat n'oppose donc pas les entreprises qui injectent des données structurées à celles qui n'en injectent pas.
Le véritable choix est ailleurs.
Il consiste à choisir entre :
posséder un site web capable d'alimenter intelligemment le Knowledge Graph et le Product Graph ;
ou rester dépendant d'une visibilité locale limitée.
Dans un monde où les IA conversationnelles, les moteurs de réponse et les systèmes de recommandation utilisent de plus en plus les graphes de connaissances pour sélectionner leurs sources, l'absence de structuration sémantique revient progressivement à devenir invisible.
La sobriété numérique ne consiste donc pas à supprimer les données. Elle consiste à éviter les données inutiles, redondantes ou mal structurées afin de concentrer les ressources informatiques sur celles qui apportent une réelle valeur.
Le défi des prochaines années ne sera probablement pas de produire davantage d'informations, mais de produire des informations suffisamment fiables, structurées et utiles pour mériter leur place dans les infrastructures numériques mondiales.
C'est précisément à cet endroit que se rejoignent le SEO, le GEO, le Knowledge Graph, le Product Graph et la transition écologique : non pas dans une logique d'accumulation, mais dans une logique de pertinence.
FAQ SEO GEO: au-delà du e-commerce le local!
En quoi l'utilisation de Shopify en boutique physique (Shopify POS) est-elle un atout pour les commerces de la Côte basque ?
L'adoption de Shopify POS (Point of Sale) permet aux caves de Saint-Jean-de-Luz, aux commerces des Halles de Bayonne ou aux producteurs du Labourd d'unifier leur site e-commerce et leur système d'encaissement sur place. Cette centralisation résout le défi de la synchronisation des stocks en haute saison: lorsqu'un produit (comme une bouteille de vin ou un produit du terroir) est scanné et vendu à un client en magasin, le stock est instantanément mis à jour à zéro sur le site internet, évitant ainsi les ruptures de stock ou les ventes impossibles à honorer en ligne.
Quel est l'impact de Shopify POS sur le SEO local et le GEO pour attirer les clients espagnols ?
L'infrastructure omnicanale de Shopify connecte nativement le stock réel des boutiques physiques avec Google Merchant Center et les fiches Google Business Profile. Lorsqu'un touriste espagnol à Biarritz ou Hendaye utilise un moteur de recherche ou une IA pour demander où trouver un produit spécifique à proximité, les algorithmes GEO peuvent affirmer avec certitude que l'article est disponible en magasin. De plus, ce système unifie le fichier client, permettant à un visiteur de Bilbao d'acheter sur place, d'intégrer un programme de fidélité et de continuer ses achats en ligne une fois rentré chez lui.
Est-il possible d'intégrer le système de caisse Shopify POS sur un site internet WordPress ?
Techniquement, il n'est pas possible d'intégrer nativement Shopify POS au sein de l'administration WordPress ou de WooCommerce pour qu'ils partagent une base de données unique. Cependant, un commerçant ou un producteur de la Côte basque peut connecter ces deux environnements via trois solutions stratégiques :
Le bouton d'achat Shopify (Shopify Buy Button) : Idéal pour un site vitrine WordPress qui vend peu de références. Les produits sont créés sur Shopify et intégrés sur WordPress via un code dédié. Le stock reste 100 % synchronisé en temps réel avec l'application Shopify POS utilisée en boutique physique.
La synchronisation par API tierce : Permet de lier une boutique WooCommerce existante à Shopify POS via des extensions (comme WP Shopify). Cette option présente toutefois un risque de latence dans la mise à jour des stocks lors des fortes affluences estivales.
L'architecture découplée (Headless) : WordPress est conservé pour sa puissance éditoriale et son SEO (le Front-End), tandis que Shopify propulse le moteur commercial et la gestion des stocks en arrière-plan (le Back-End).
L'arbitrage SEO/GEO : Si l'activité en magasin physique est prioritaire, migrer l'intégralité du site WordPress vers Shopify offre une infrastructure omnicanale native, sans bug de synchronisation, maximisant ainsi la visibilité des stocks locaux sur Google Merchant Center et les moteurs de réponse.
Quelles données structurées Shopify POS injecte-t-il concrètement dans le Product Graph de Google ?
L'écosystème Shopify injecte automatiquement le schéma Product (Schema.org), qui nourrit directement le Product Graph de Google pour identifier et référencer vos articles. La force de la synchronisation avec Shopify POS (la caisse physique) est l'injection de données transactionnelles et géolocalisées en temps réel à travers des triplets sémantiques stricts :
Identifiants d'autorité uniques : Le système transmet les codes gtin13 (EAN), mpn (référence fabricant) et brand (la marque). Cela permet aux IA de certifier que votre produit est exactement le même objet que celui mentionné sur d'autres sources du web.
L'offre commerciale (Offer) : Le prix (price), la devise (priceCurrency) et l'état de l'article (itemCondition).
Le triplet de disponibilité locale : C'est ici que Shopify POS fait la différence. Il génère la propriété availableAtOrFrom connectée à l'entité LocalBusiness (votre boutique ou votre cave). Le moteur de recherche reçoit le triplet : [Votre Produit] → disponibilité → En stock ET [En stock] → valable à → [Adresse de votre boutique aux Halles de Bayonne]. À chaque encaissement sur place, le niveau de stock est actualisé dans le Product Graph.
Une réconciliation d'entités entre Shopify et la fiche Google Business Profile est-elle nécessaire pour revendiquer ses triplets sémantiques ?
Oui, cette réconciliation est indispensable pour unifier vos performances. Par défaut, les algorithmes séparent l'entité numérique (votre boutique Shopify ancrée dans le Product Graph) et l'entité physique (votre magasin ou cave sur la Côte basque ancré dans le Knowledge Graph). Pour valider vos triplets sémantiques locaux et permettre aux IA de certifier qu'un produit est disponible immédiatement pour un utilisateur à proximité, vous devez lier ces deux mondes. Cette réconciliation s'effectue techniquement en injectant l'identifiant unique (URL ou code CID) de votre fiche Google Business Profile dans les données structurées de Shopify à l'aide de la propriété sameAs.
Peut-on configurer un fil d'ariane de qualité avec Shopify pour lier ses produits et services au Knowledge Graph ?
Le fil d'Ariane (BreadcrumbList) ne se gère pas dans l'application de caisse Shopify POS, mais sur la boutique en ligne Shopify qui centralise les données. Shopify permet de générer des fils d'Ariane sémantiques très puissants, essentiels pour structurer l'arborescence ontologique de votre site et créer un nœud d'autorité dans le Knowledge Graph.
Pour obtenir un fil d'Ariane de haute qualité sémantique avec Shopify, il faut veiller à deux aspects techniques :
L'imbrication des collections : Par défaut, Shopify a tendance à générer des URL de produits plates (/products/nom-du-produit). Pour pousser une hiérarchie claire aux moteurs de réponse (ex: Accueil → Terroirs du Sud-Ouest → Caves et Spiritueux → Nom du produit), il faut configurer le thème pour qu'il intègre le chemin de la collection dans le fil d'Ariane et dans l'URL.
La distinction Produits vs Services : Pour un établissement qui vend à la fois des produits physiques (bouteilles, produits régionaux) et des services (ateliers œnotouristiques, visites de caves), le fil d'Ariane aide les algorithmes GEO à trier l'information. Il va pousser les pages produits vers le Product Graph (via le tunnel de collections) et ancrer les pages de services directement au nœud parent LocalBusiness (votre adresse physique configurée dans Shopify POS) au sein du Knowledge Graph.
Faut-il appliquer la réconciliation d'entités sur toutes les pages de son site Shopify ?
Non, appliquer la réconciliation partout serait une erreur sémantique qui générerait du bruit algorithmique. Chaque type de page sur Shopify possède son propre rôle ontologique. La réconciliation doit être injectée de manière chirurgicale selon la typologie de la page :
Sur la page d'accueil et la page contact : C'est le point d'ancrage principal de l'entreprise. On y déploie le schéma LocalBusiness (ou Winery pour une cave) en y intégrant la propriété sameAs pointant vers la fiche Google Business Profile et les réseaux sociaux d'autorité. Le triplet revendiqué est : [Mon Site Web] → sameAs → [Ma Fiche Physique Google Maps].
Sur les pages Produits (/products/) : L'objectif ici est le Product Graph. On n'utilise pas le tag sameAs vers Google Maps directement sur le produit. À la place, on utilise la propriété availableAtOrFrom au sein du bloc Offer. C'est le canal Google de Shopify qui se charge de lier le produit à l'identifiant de la boutique configurée dans Shopify POS. Le triplet devient : [Mon Produit] → availableAtOrFrom → [Mon Magasin Physique].
Sur les pages de Services (ateliers œnotouristiques, dégustations) : On utilise le schéma Service ou Event en qualifiant la propriété provider (le fournisseur du service), qui doit pointer vers le schéma LocalBusiness de votre établissement. Le triplet validé est : [Mon Atelier Dégustation] → provider → [Ma Boutique Physique].
Pourquoi conseille-t-on de densifier la réconciliation d'entités sur un site Hostinger Builder, mais de la segmenter sur Shopify POS?
La différence de stratégie ne réside pas dans l'objectif sémantique, mais dans l'architecture technique du CMS utilisé pour capter les recherches exploratoires et transactionnelles :
Sur un site vitrine ou catalogue (comme Hostinger Website Builder) : Les données ne sont pas interconnectées nativement avec un moteur de stock ou de caisse physique. Le CMS est techniquement "plat". Pour bâtir une entité dense, incontournable et forcer les moteurs de réponse (GEO) à lier chaque contenu à votre autorité réelle, il faut injecter manuellement les triplets d’identité et le lien sameAs (vers la fiche Google ou Instagram) sur un maximum de pages (articles, services, profil). Cela sature le code pour prouver aux IA l'origine et la paternité physique de chaque texte.
Sur un écosystème e-commerce omnicanal (comme Shopify + Shopify POS) : Le CMS est un moteur de base de données relationnelle déjà automatisé. Les rôles y sont segmentés par nature : la réconciliation globale se fait à la racine (page d'accueil) via le sameAs, tandis que les pages produits transmettent dynamiquement leurs propres triplets de disponibilité locale (availableAtOrFrom) au Product Graph de Google. Forcer manuellement un schéma local sur chaque page produit Shopify créerait ici un bruit algorithmique et une redondance inutile.
En résumé : On densifie manuellement partout lorsque le CMS est statique (Hostinger) pour forcer la reconnaissance de l'entité ; on orchestre de manière chirurgicale lorsque le CMS gère nativement les flux physiques et numériques (Shopify POS).
L’application Shopify POS permet-elle de diviser ou d’accepter plusieurs moyens de paiement comme les espèces, les chèques et la carte cadeau « Pays Basque au Cœur » ?
Oui, Shopify POS gère nativement le multi-paiement et offre une flexibilité totale lors de l’encaissement en boutique physique ou sur les marchés de la Côte basque. Une brasserie à Biarritz, une cave à Saint-Jean-Pied-de-Port ou un producteur à Mauléon peuvent diviser une même transaction en acceptant plusieurs modes de règlement :
Les espèces (liquide) et les chèques : L'application intègre des boutons de paiement personnalisés permettant d'enregistrer ces transactions, de calculer le rendu de monnaie et d'ouvrir le tiroir-caisse physique connecté.
Les cartes bancaires (cartes bleues) : Traitées de manière sécurisée via les terminaux de paiement Shopify (lecteurs WisePad ou POS Terminal), mettant instantanément à jour le flux financier de la boutique.
Les cartes cadeaux propres à la boutique : Shopify permet d'émettre et de scanner ses propres cartes cadeaux numériques ou physiques, utilisables aussi bien sur le site web qu'en magasin.
La carte cadeau territoriale « Pays Basque au Cœur » (PBAC) : Pour les commerces affiliés à ce réseau de proximité (souvent géré par l'association des commerçants de l'intérieur et du littoral), l'encaissement se fait très simplement sur Shopify POS. Le commerçant configure un moyen de paiement personnalisé nommé "Carte Cadeau Pays Basque au Cœur". Lors de l'achat, il sélectionne cette option pour solder la vente sur la tablette, puis traite la carte ou le chèque cadeau via la plateforme partenaire de l'association pour son remboursement futur.
EUSKAL CONSEIL
9 rue Iguzki alde
64310 ST PEE SUR NIVELLE
07 82 50 57 66
euskalconseil@gmail.com
Mentions légales: Métiers du Conseil Hiscox HSXIN320063010
CGV & Mentions légales
Ce site utilise uniquement Plausible Analytics, un outil de mesure d’audience respectueux de la vie privée. Aucune donnée personnelle n’est collectée, aucun cookie n’est utilisé.